ViT-Transformer Is All You Need
ViT:Transformer Is All You Need
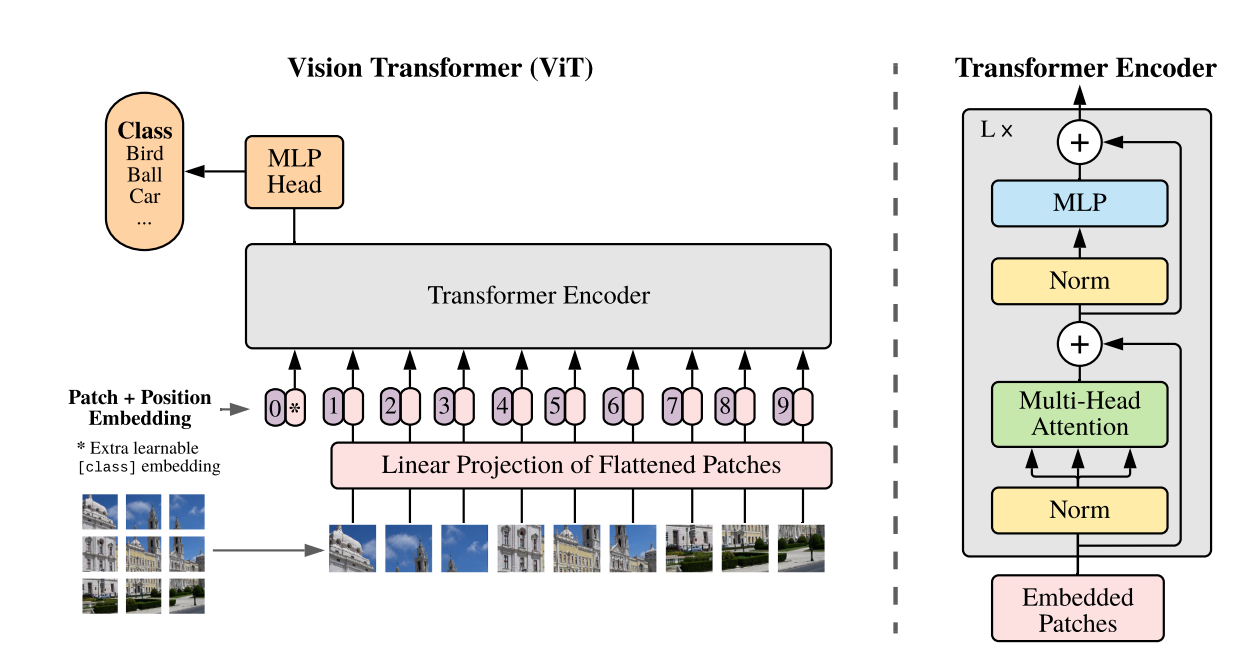
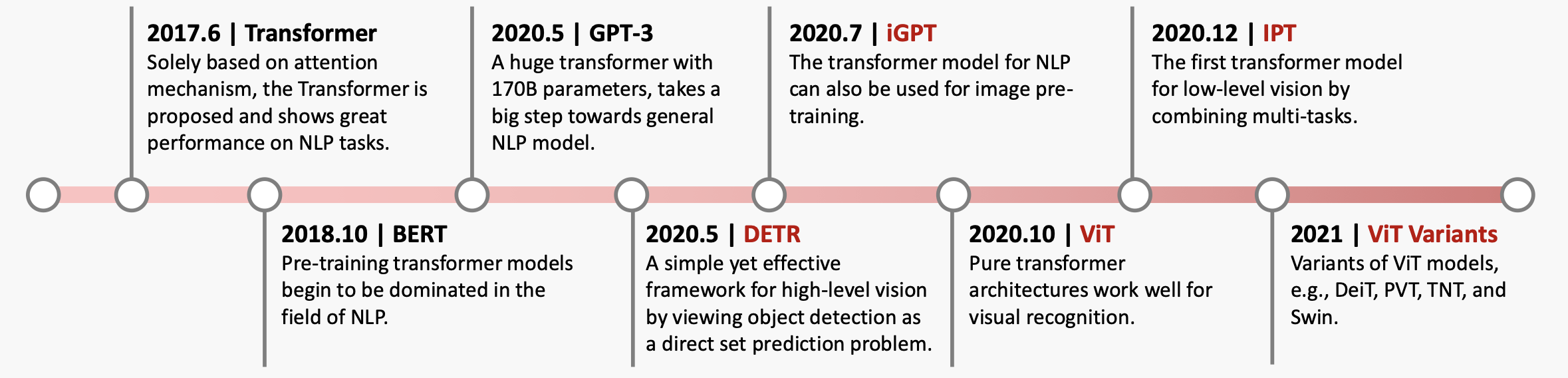
Patch Embedding
将原始的2-D图像转换成一系列1-D的patch embeddings,分成patch有利于降低计算量。
Position Embedding
ViT中默认采用学习(训练的)的1-D positional embedding,在输入transformer的encoder之前直接将patch embeddings和positional embedding相加。
Class Token
增加一个特殊的class token,其最后输出的特征加一个linear classifier就可以实现对图像的分类。class token对应的embedding在训练时随机初始化,然后通过训练得到。
Hybrid Architecture
先用CNN对图像提取特征,从CNN提取的特征图中提取patch embeddings。
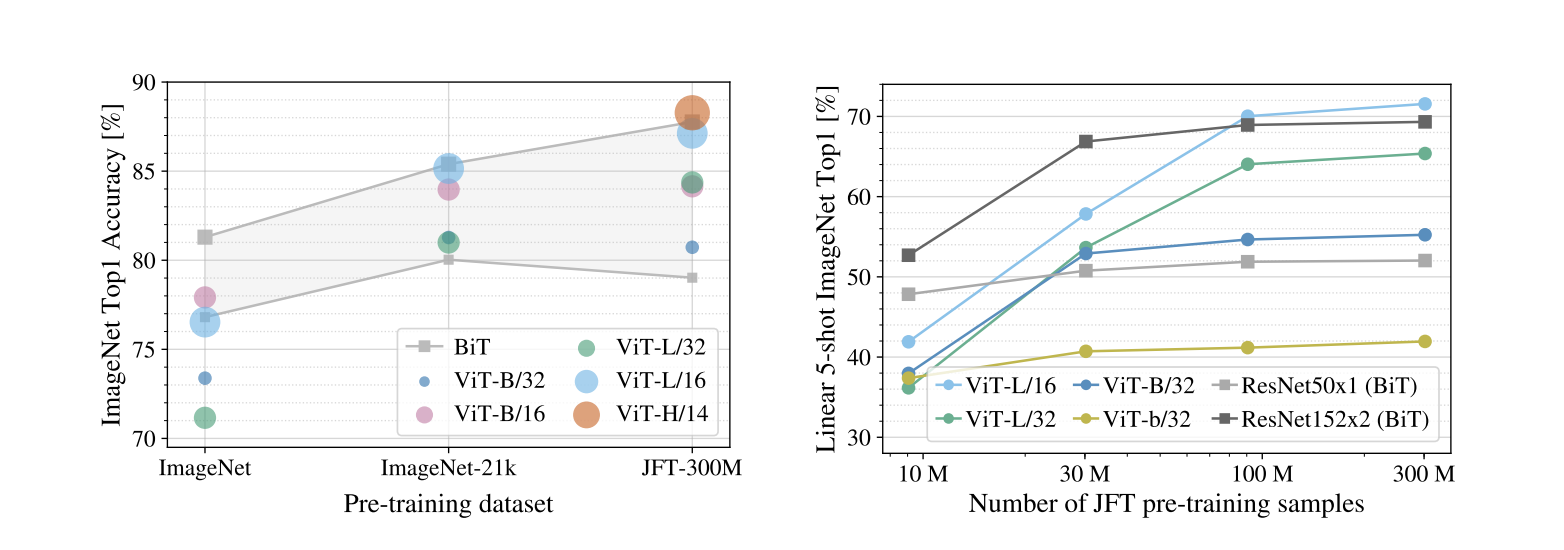
EXPERIMENTS
数据量达到一定规模后效果超过CNN。
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
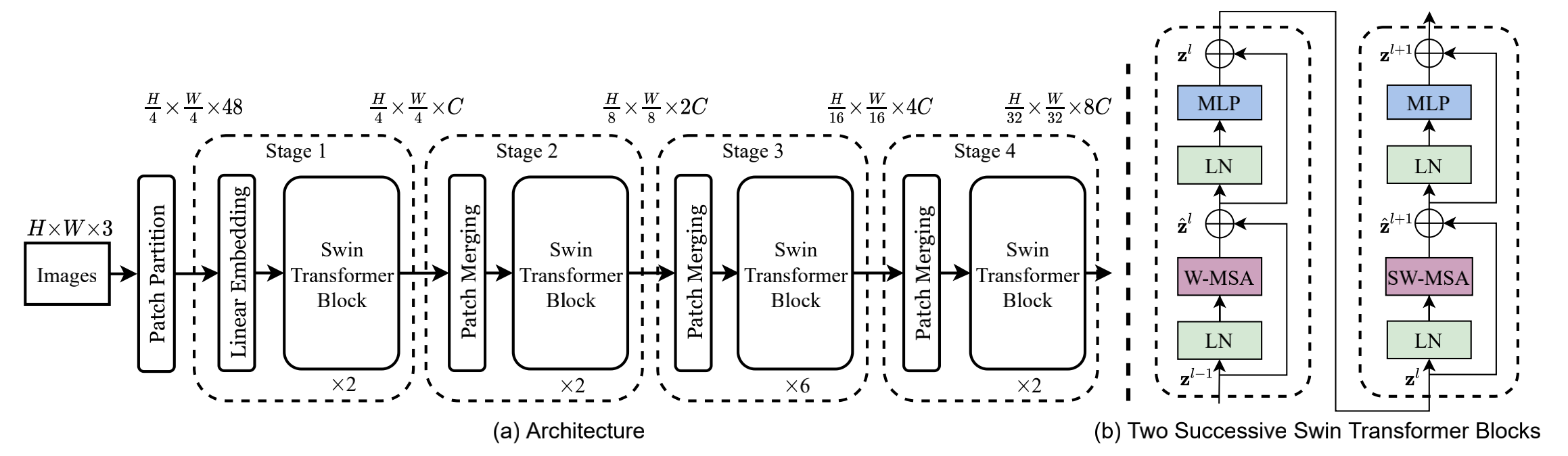
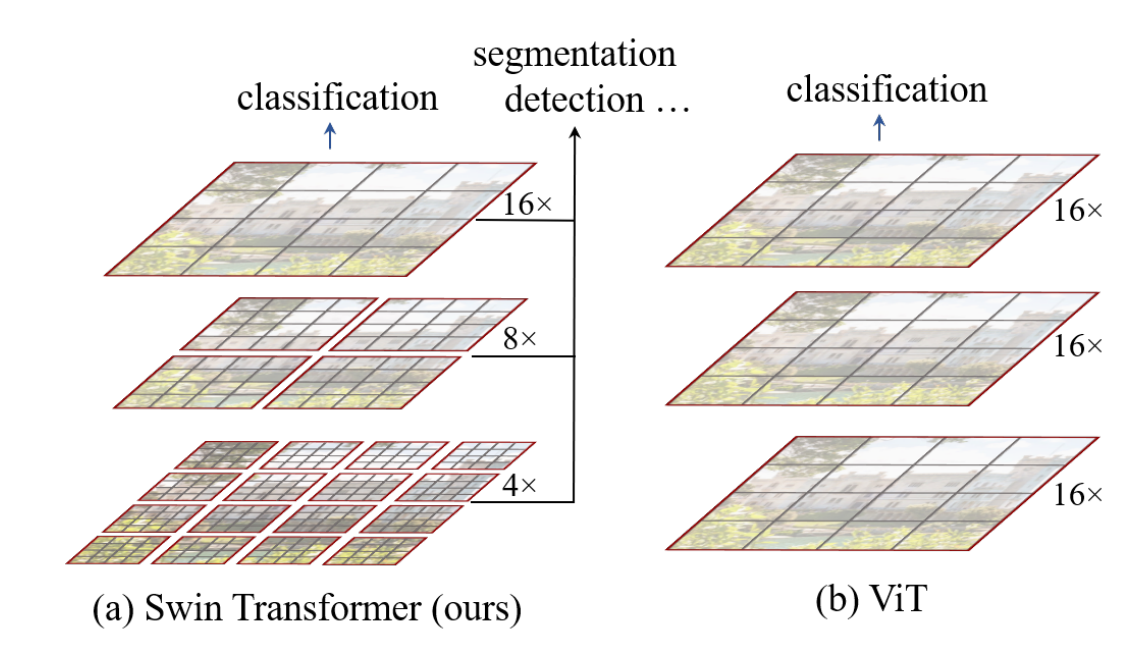
Compare to ViT
Swin Transformer模仿CNN, 随着层数加深,逐步减少feature map大小(token 数量),增加feature map 维度(channel 数),提取了层次化的特征。
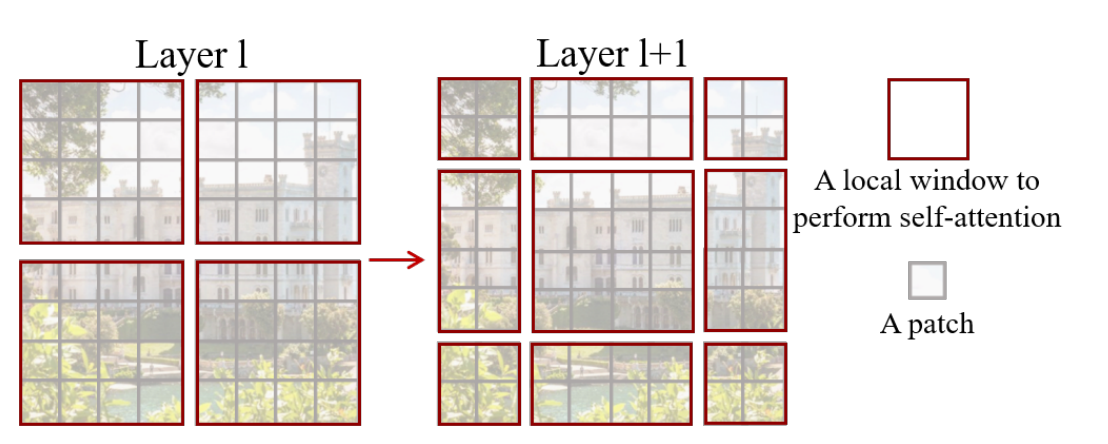
W-MSA & SW-MSA
规定只在局部范围内做self-attention,不做对全局token的attention,可以减少计算量。于是作者提出了Window based Self-Attention (W-MSA),每个token的attention范围限定在一个window中(包含M*M patch)。
分window计算self-attention之后,window之间缺乏联系,限制了模型的感受野,提出Shifted Window based Self-Attention (SW-MSA),加入位置偏移,每次shift (M/2, M/2)像素。
相邻的Swin Transformer Block交替使用W-MSA和SW-MSA。
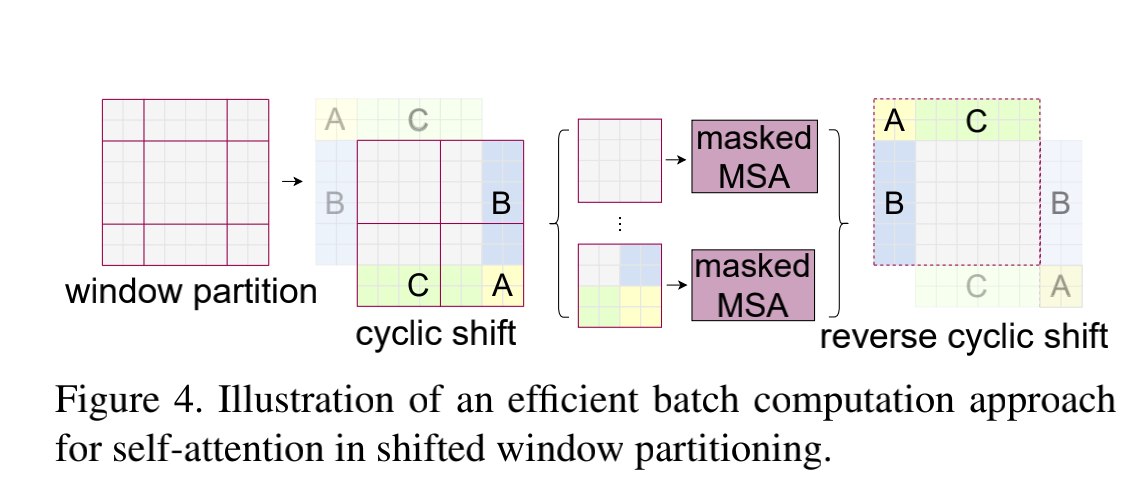
Effificient batch computation for shifted confifiguration
cyclic shift操作:将图中浅色的ABCwindows转移到深色ABC的填充部分,使得每个windows都能够保持原来的大小,同时使得window数与偏移前一致,保持原有的计算量。
mask方法:采用 masked MSA 机制将 self-attention 的计算限制在每个子窗口内,把不需要的 attention 值给它置为0,避免属于不同 sub-window的patch之间 attention 发生交叠。
Position Embedding
Swin Transformer 的位置编码 是加在 Attention 矩阵上的,位置编码后必然是个9×9的矩阵。
比如位置编码 的第
个元素
,它代表的是 Window 里面第
个 Patch 和第
**个 Patch 的相对位置关系,相同位置关系的编码值相同。
ViT-Transformer Is All You Need

