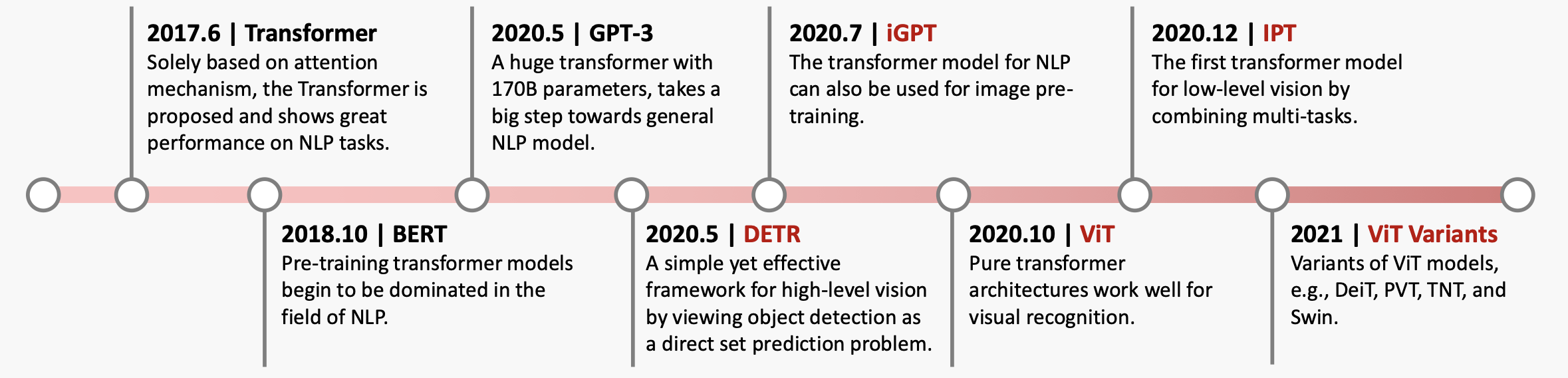
On Trend Analysis of Prompt Learning


在传统的长尾分布处理方法中,普遍使用的重采样、重加权等re-balancing办法可能导致对头部类欠拟合且对尾部类过拟合,从而产生shortcut。而Decoupling为代表的二阶段训练方法则不太符合深度学习端到端的理念。
人类在观察物体的时候,在总体对目标进行把握的时候,通常不是将目光放到整个物体上,而是按照一定的次序对物体进行扫描,有选择地将注意力集中到某些位置上,然后将这些区域信息进行汇总处理。通过不同时间下不同位置信息的组合,建立场景的表征,来指导眼睛的关注点。这样就将计算资源集中到了有价值的信息上,从而节省了带宽。