背景和动机
人类在观察物体的时候,在总体对目标进行把握的时候,通常不是将目光放到整个物体上,而是按照一定的次序对物体进行扫描,有选择地将注意力集中到某些位置上,然后将这些区域信息进行汇总处理。通过不同时间下不同位置信息的组合,建立场景的表征,来指导眼睛的关注点。这样就将计算资源集中到了有价值的信息上,从而节省了带宽。
核心思想
将Attention看成是由目标引导的一个序列决策过程,鉴于当时条件的限制及CNN发展的阶段,采用 RNN 模型建模,然后通过 Attention及强化算法来决定序列各阶段模型该看图片的哪个 patch,来获取任务相关的关键信息,过滤无关信息,这样模型计算量与图片的输入尺寸相互独立,从而减少计算量。强化学习算法主要用来模拟与环境交互,每一时间点智能体只根据限制频域或空域的范围提取信息,它自主选择感知域,并通过奖惩机制获得反馈,并实现收益的最大化。
1.模型
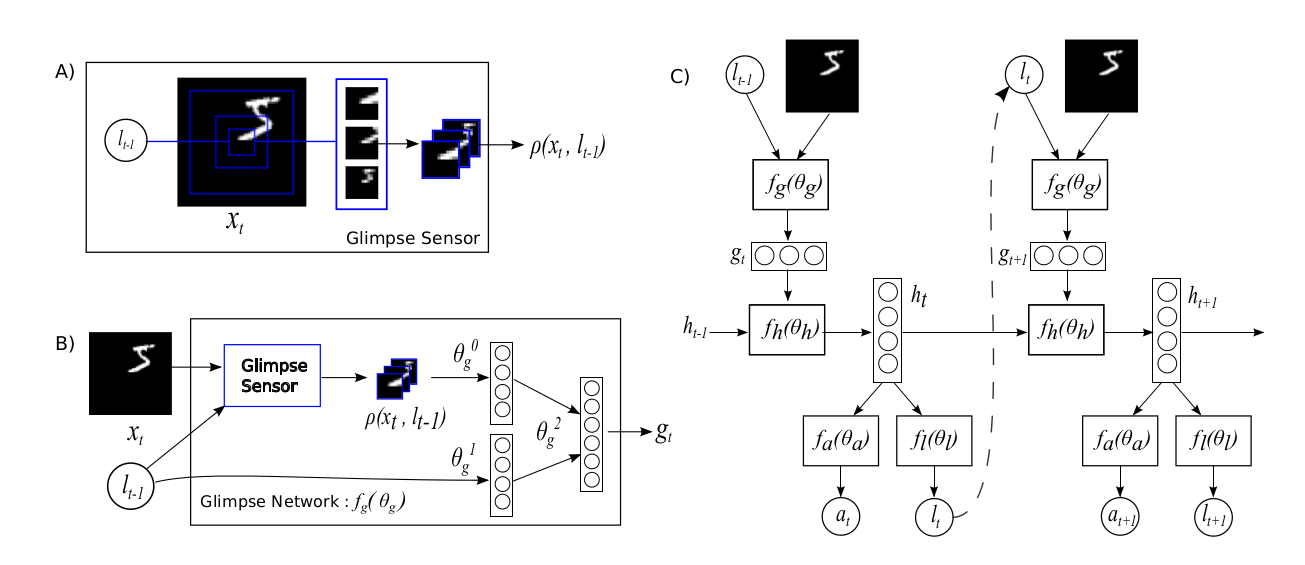
各模块介绍如下
Glimpse Sensor
结构如图A所示,以位置信息
$l_{t-1}$
为中心,长宽为
$w$
的倍数提取图像 patch,即 attention region,将提取的区域归一化到
$w * w$
大小,拼接得到输入
$\rho\left(x_{t}, l_{t-1}\right)$
,从而把不同层次的信息组合了起来,并且起到减少计算量和噪声影响的作用。
Glimpse Network
结构如图B所示,输入层次信息
$\rho\left(x_{t}, l_{t-1}\right)$
后通过网络
$f_{g}\left(\theta_{g}^{0}\right)$
得到潜在层次信息,位置信息
$l_{t-1}$
通过网络
$f_{g}\left(\theta_{g}^{1}\right)$
得到潜在位置信息,将两种信息经过网络
$f_{g}\left(\theta_{g}^{2}\right)$
处理得到RNN的输入向量
$g_{t}$
。
Action and Location Extractor
结构如下所示,

输入信息
$g_{t}$
和前一阶段历史信息
$h_{t-1}$
经由RNN得到下一阶段输入的隐藏层信息,而隐藏层信息通过不完全可观察马尔科夫决策过程(POMDP)得到下一动作
$a_{t}$
和下一阶段的位置信息
$l_{t}$
。
整体结构:
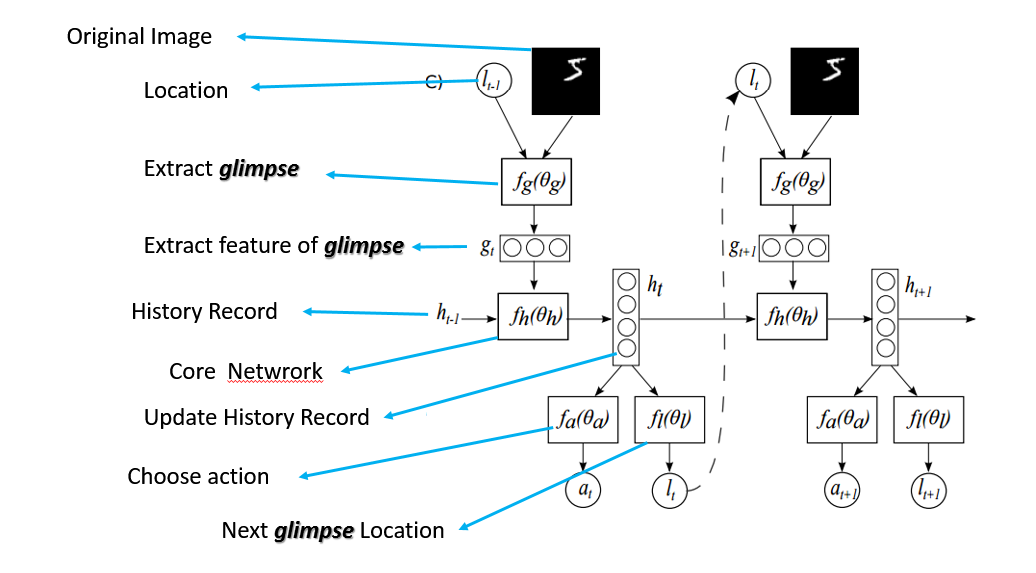
2.训练
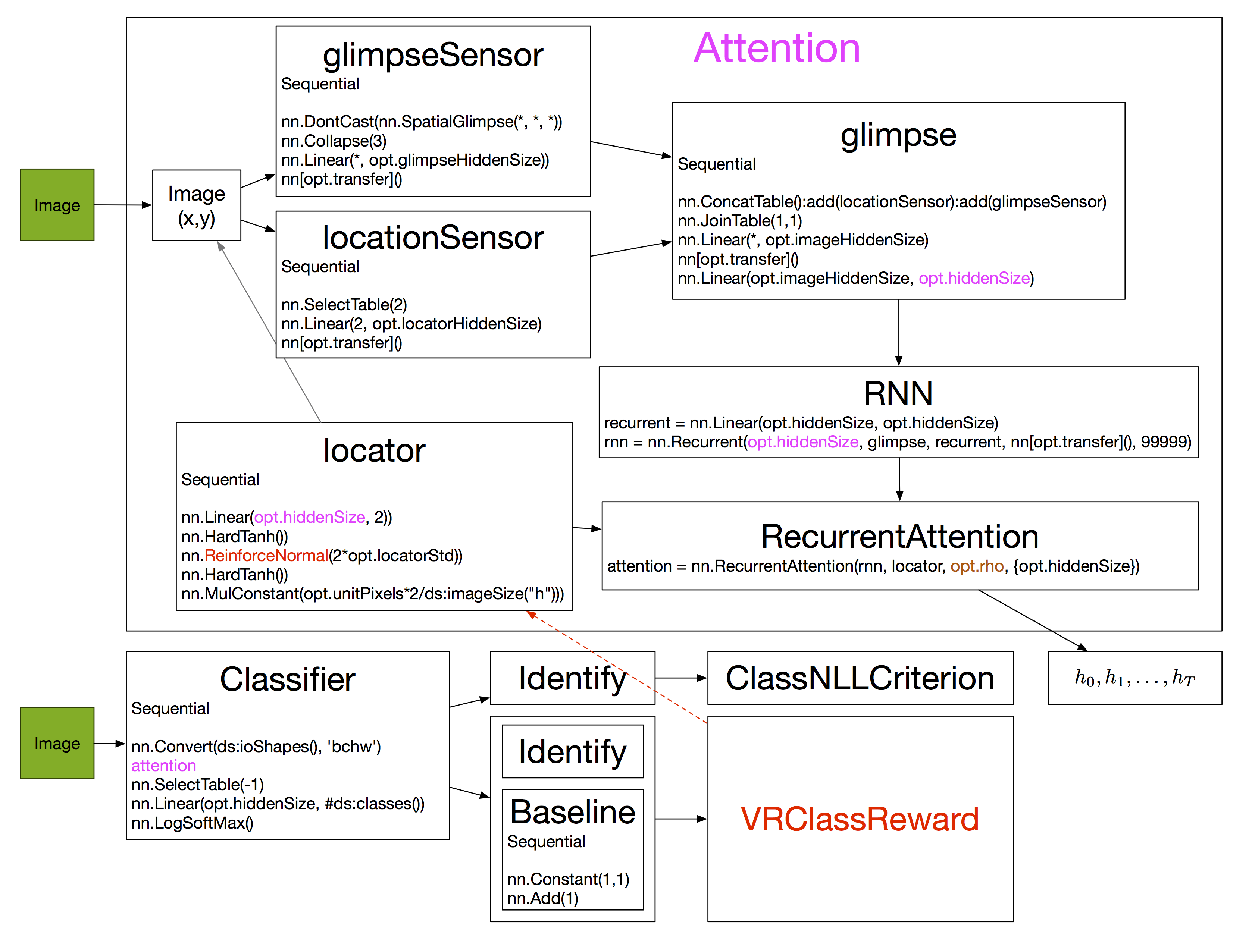
训练目标:使得总奖励最大
$$
J(\theta)=\mathbb{E}_{p} p\left(s_{1: T} ; \theta\right)\left[\sum_{t=1}^{T} r_{t}\right]=\mathbb{E}_{p\left(s_{1: T} ; \theta\right)}[R]
$$
REINFORCE方法:取经验平均求解(样本近似)的方法来逼近梯度:
$$
\nabla_{\theta} J=\sum_{t=1}^{T} \mathbb{E}_{p\left(s_{1: T} ; \theta\right)}\left[\nabla_{\theta} \log \pi\left(u_{t} \mid s_{1: t} ; \theta\right) R\right] \approx \frac{1}{M} \sum_{i=1}^{M} \sum_{t=1}^{T} \nabla_{\theta} \log \pi\left(u_{t}^{i} \mid s_{1: t}^{i} ; \theta\right) R^{i}
$$
反向传播训练:通过REINFORCE得到
$f_{a}$
和
$f_{l}$
的梯度信息。然后反向依次训练RNN, Glimpse Network。对于分类问题,由于
$a_{T}$
是确定,最大化
$\log \pi\left(a_{T} \mid s_{1: T} ; \theta\right)$
,通过优化
$f_{a}$
的交叉熵得到梯度,反向训练模型。
理论依据
1.RNN&HMM
整个模型过程可以看做是一个局部马尔科夫决策过程。每个阶段的动作和位置只与上一阶段的动作和位置有关,从而控制模型的参数和计算量,使之摆脱输入图像的大小的约束。展开RNN结构,以时间为序,整个过程可表示为
$s_{1: t}=x_{1}, l_{1}, a_{1}, \ldots, x_{t-1}, l_{t-1}, a_{t-1}, x_{t}$
。根据上一阶段的动作
$a_{t}$
和位置
$l_{t-1}$
, 从输入图像提取出信息,通过模型网络,输出特征信息。按照个人理解,这一方法可行性是基于RNN把上下文状态在每一个时间点进行更新,并保存下来,具有天然的马尔科夫特性,并且具有非线性拟合的优势。
2.强化学习
在执行一个动作之后, agent会收到一个环境中得到的新的视觉观祭
$\mathrm{x}{\mathrm{t}+1}$
和一个奖励信号
$\mathrm{r}{\mathrm{t}+1}$
。在目标识别场景中,如果分类正确,就奖励1分,否则奖励就设置为0,从而利用POMDP决定出下一阶段的动作
$a_{t}$
和位置
$l_{t}$
。奖惩机制为agent提供额外信息辅助,来决定如何行动和如何最有效的布置感知器。
实验结果
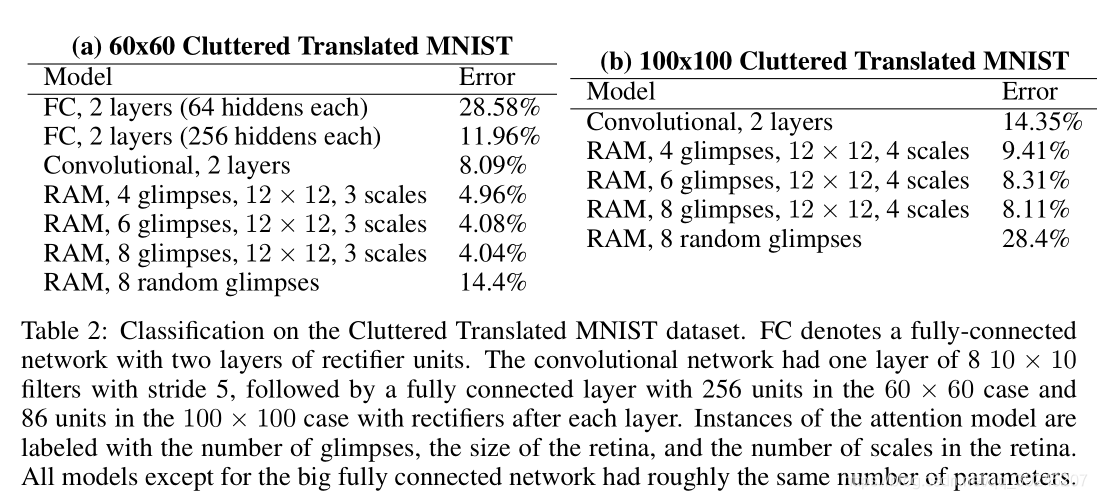
本文描述了一个端到端的优化序列,能够直接训练模型,最大化一个性能衡量,依赖于该模型在整个任务上所做的决策。按照时间顺序处理输入,一次在一张图像中处理不同的位置,逐渐的将这些部分的信息结合起来,来建立一个该场景或者环境的动态间隔表示。利用反向传播来训练神经网络的成分和策略梯度来解决控制问题的不可微性。

