Long-Tailed Classification by Keeping the Good and Removing the Bad Momentum Causal Effect NIPS,2020
背景和动机

在传统的长尾分布处理方法中,普遍使用的重采样、重加权等re-balancing办法可能导致对头部类欠拟合且对尾部类过拟合,从而产生shortcut。而Decoupling为代表的二阶段训练方法则不太符合深度学习端到端的理念。
核心思想
- multi-head normalized classifier $$ Y_{i}=\frac{\tau}{K} \sum_{k=1}^{K}+\frac{\left(w_{i}^{k}\right)^{T} x^{k}}{\left(\left\|w_{i}^{k}\right\|+\gamma\right)\left\|x^{k}\right\|} $$其中$$ \tau, \gamma $$是超参,K是multi-head的数量
2.统计一个移动平均特征
\bar{x}
$$
\hat{d}=\bar{x} /|\bar{x}|$$
3.从training的logits中剔除代表对头部类过度倾向的部分,即测试时改用如下公式计算TDE logits:
理论依据
1.因果图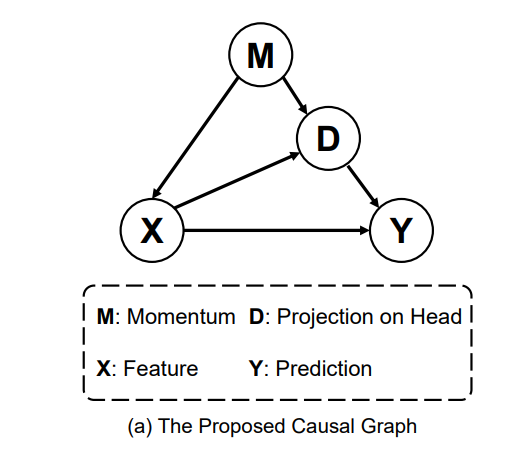
通常意义上,在因果推断理论中,M是对推断X->Y的混淆因子,D则是中介因子,它们都有可能对推理的正确性产生影响。
而在当前的问题中,M就是优化器的动量,X是backbone提取的核心特征,Y是预测。D是特征对头部大类的偏移量。
2.De-confound-TDE
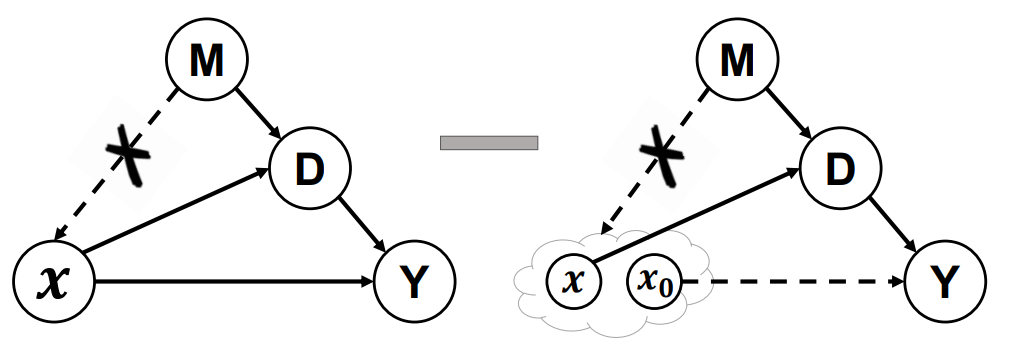
(1)使用De-confound training在训练中控制M对X的影响,但是因为无法统计M的真实分布,通过multi-head多重采样来近似。
(2)把原始的logits当成是X对Y的因果效应,根据propensity score(排除协变量的影响)思想,应该对大类和小类等所有类做归一化统一分布,将其实现为一种logits的normalization,其中包含类别相关与类别不相关两个normalization项。
(3)counterfactual inference做减法,通过安慰剂对照组,去除了间接效应。
3.不同策略分类效果对比
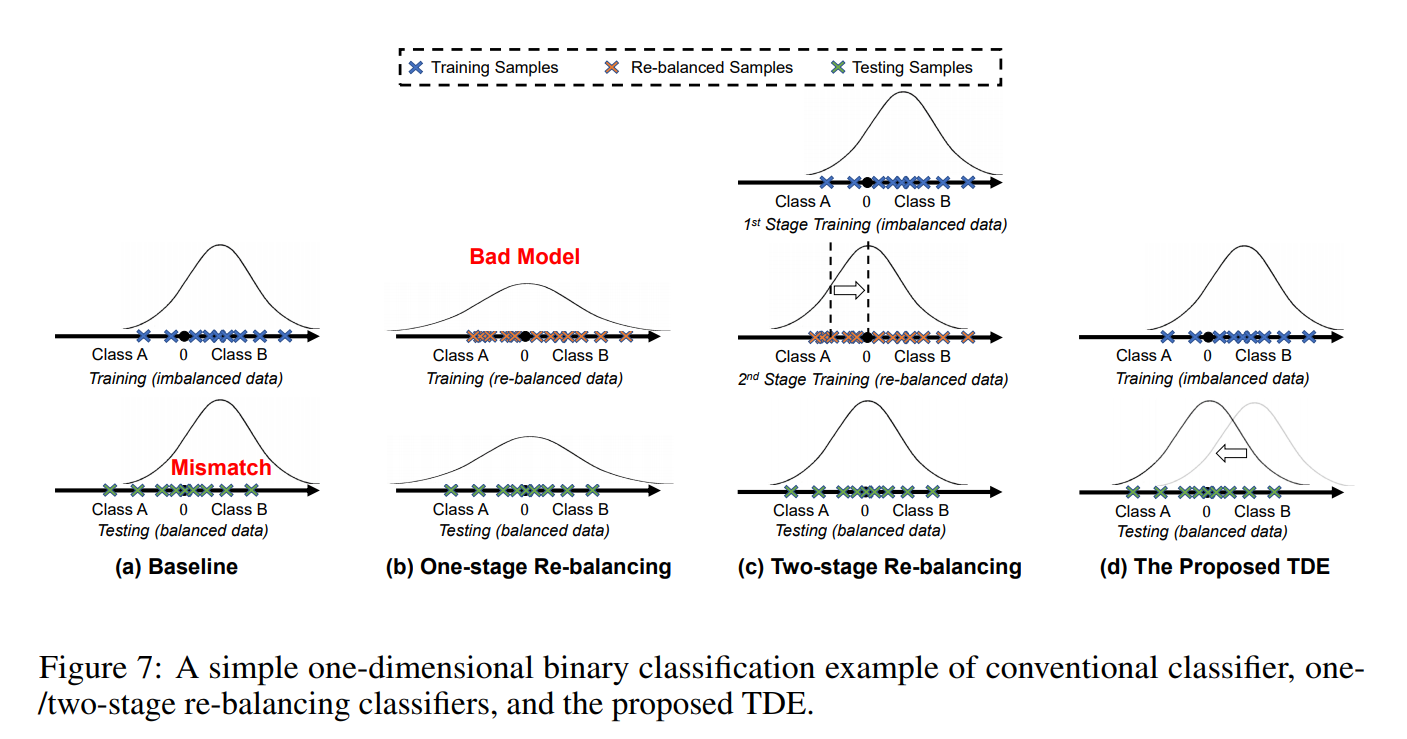
根据预测分布,可以看出直接训练和one-stage的re-balancing都有严重的问题,而two-stage的方法通过再训练去矫正分类边界。TDE方法则直接矫正特征本身的分布,从而解决长尾问题。
实验结果
1.在mageNet-LT和Long-tailed CIFAR-10/-100上的表现
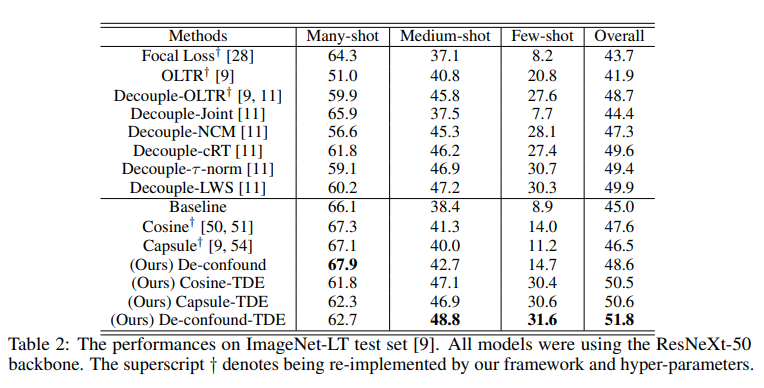
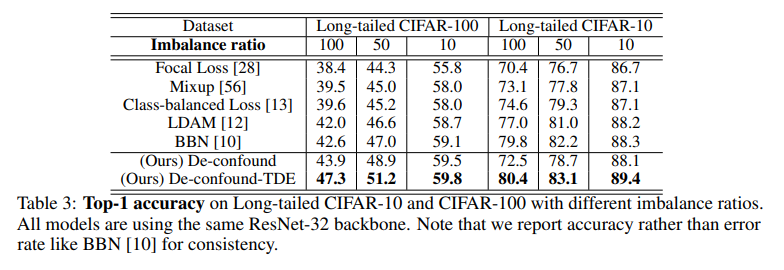
可以看出TDE方法在长尾数据集上表现较以往的算法有明显提升。
2.feature map可视化

发现De-confound-TDE使得feature map更加关注高区分度的特征。
Long-Tailed Classification by Keeping the Good and Removing the Bad Momentum Causal Effect NIPS,2020

