Black-box Modal & Knowledge Distillation
Unsupervised Domain Adaptation for Segmentation withBlack-box Source Model
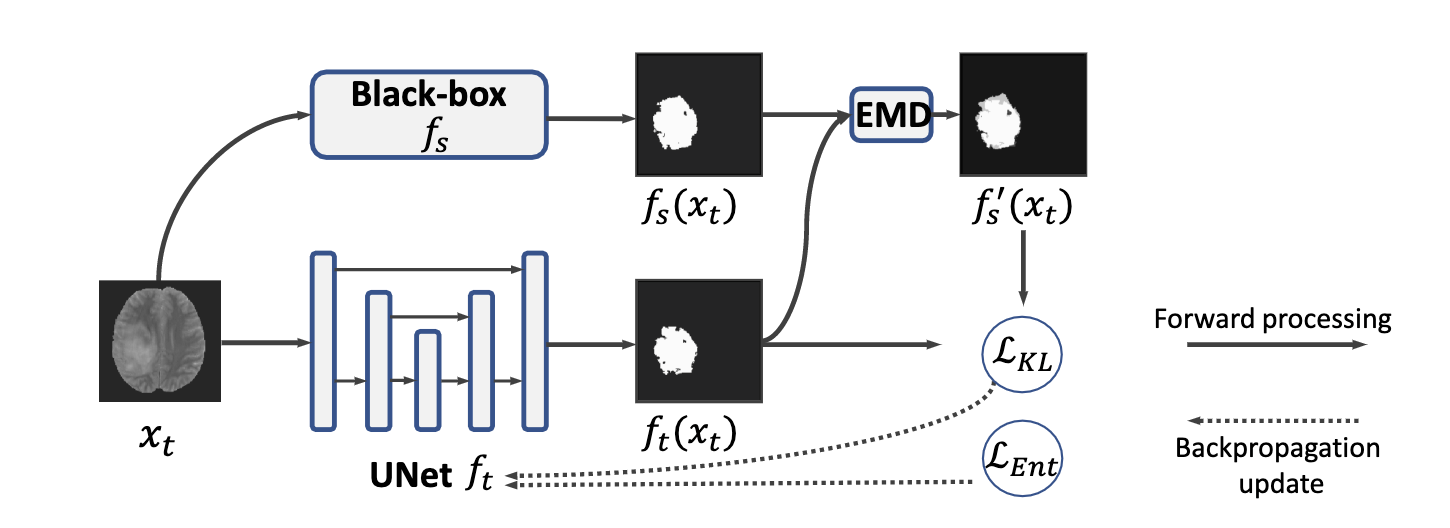
采用了一种带有指数混合衰减(EMD)的知识提炼方案来逐步学习目标特定的表征。 此外,无监督的熵最小化被进一步应用于目标领域信心的正规化。 采用自我训练方案来构建目标域训练的伪标签。具体来说,为了实现对目标域的逐步转换,将源域和目标域的预测混合起来,即 fs(xt)和ft(xt),并通过EMD调整它们的比例来获得伪标签:y′tn=λfs(xt)n+(1-λ)ft(xt)n,(1)其中eren指的是像素,fs(xt)n和ft(xt)n分别是预测sf(xt)和ft(xt)的第3个像素的softmax输出的柱状图分布。 λ=λ0exp(-I)是一个目标适应矩参数,在迭代I时呈指数衰减。 使用EMD伪标签的损失知识提炼可以表述为:LKL=1H0×W0H0×W0XnDKL(ft(xt)n||y′tn),(2)其中H0和W0是图像的高度和宽度。 因此,λ的权重可以随着训练的进行而平滑地降低,而ft逐渐代表目标数据。 此外,还可以在我们的框架之上增加一个无监督的训练方案,例如熵最小化。 为了便于实施,像素分割的熵可以被表述为像素级softmax预测的平均熵,由LEnt=1H0×W0H0×W0Xn{ft(xt)nlogft(xt)n}给出。 (3)最小化LEnt会导致输出ft(xt)n接近于单热分布,总之,我们的训练目标可以表述为L=LKL+αLEnt,(4)其中α用于平衡EMD伪标签的知识提炼和熵的小型化。 熵最小化的一个微不足道的解决方案是,所有未标记的目标数据可能具有相同的单热编码。因此,为了稳定训练,我们将超参数α从5线性变为0。


Divide to Adapt: Mitigating Confirmation Bias forDomain Adaptation of Black-Box Predictors
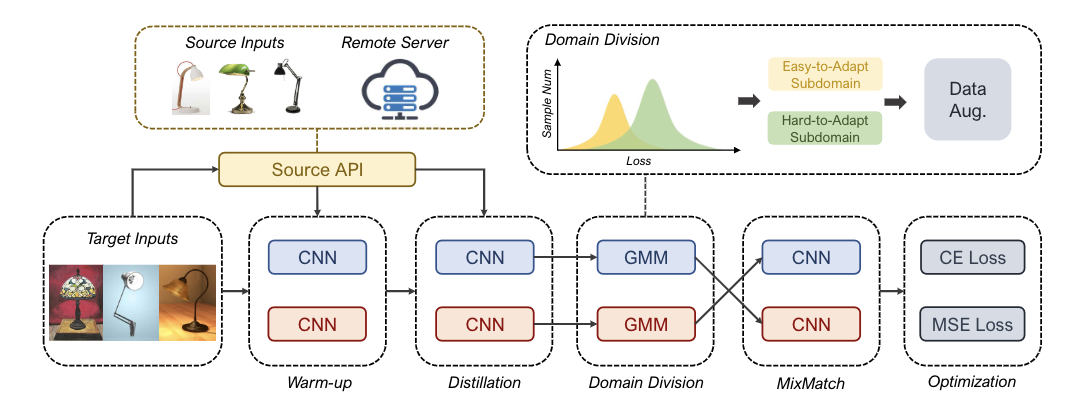
提出在不放弃任何样本的情况下充分利用目标域,逐步缓解确认偏差。这是通过一种新的 “划分-适应 “策略实现的,其中目标域被划分为一个无噪声的易于适应的子域和一个难以适应的子域。该领域的划分是由一个观察结果促成的:深度模型倾向于学习干净的样本,而不是嘈杂的样本。在DABP的知识蒸馏的早期阶段,我们发现损失分布中出现了两个峰值,可以用高斯混合模型(GMM)来进行领域划分。关于容易适应的子域是一个标签集,难以适应的子域是一个无标签集,我们可以利用流行的半监督学习方法来解决DABP问题。新提出的策略净化了目标域,减少了错误积累,同时充分利用了所有的目标数据集。在这种方式下,本文提出了黑匣子模式适应性的Domain分部(BETA),它由两个关键模块组成,以逐步抑制确认偏差。 具体来说,如图所示,模型首先通过对源预测器的知识提炼进行预热,然后根据适合损失分布的GMM进行域划分。利用这两个子域,BETA采用MixMatch来充分利用所有的目标域数据进行训练。为了进一步缓解确认偏差,BETA提出了相互教导的双胞胎网络,其中一个网络从另一个网络的领域划分中学习,而领域划分则通过增强和Mixup技术发散,强制两个网络以不同的方式执行并过滤彼此的错误。从BETA的理论分析来看,两个子域之间的分布差异也很重要,因此可以作为一个额外的学习目标。 (i) 我们为DABP问题提出了一个新的BETA框架,它可以迭代地抑制来自黑箱源域预测器的模型适应的错误积累。 就我们所知,这是第一个解决DABP的确认偏差的工作。(ii) 我们从理论上表明,目标域的误差被难以适应的子域的噪声比所限制,并从经验上表明,这一误差被BETA所最小化。
Unsupervised Domain Adaptation of Black-Box Source Models
提出了一种简单而有效的方法,即带噪声标签的迭代学习(IterLNL)。IterLNL以黑盒模型作为噪声标签的工具,迭代地进行噪声标签和噪声拉贝尔学习(LNL)。 为了便于在B2UDA中实现LNL,我们从未标记的目标数据的模型预判中估计了噪声率,并提出了类别明智抽样法来解决类别间不平衡的标签噪声。 在基准数据集上的实验显示了IterLNL的功效。在既没有源数据也没有源模型的情况下,IterLNL的表现与充分利用标 记源数据的传统UDA方法相当。
On Universal Black-Box Domain Adaptation
学习任务可以转换为两个子任务,即类内识别和类外检测,它们可以分别通过模型蒸馏和熵分离来学习。 我们建议将它们统一到一个自我训练的框架中。
提出了一个更实用的通用黑箱领域适应(UB2DA)的设置,我们通过允许目标标签空间的变化和未知,进一步放松了限制。与闭合集黑箱适应不同的是,UB2DA允许目标标签空间变化和未知。不同于封闭式黑盒领域适应,提议的UB2DA旨在学习一个稳健的目标预测模型,不仅能识别类内目标实例,还能检测类外实例。具体来说,类内判别是通过模型蒸馏学习一个多类分类器来实现的,我们用一个通过熵值分离学习的二元分类器进行类外检测。 然后,我们建议将这两个子任务统一到自我训练框架中,通过目标样本的局部邻域的预判的一致性进行规范化。 这样的学习框架简单、稳健、容易优化;它也与自我训练的理论发现保持一致的目标。
DINE-Domain Adaptation from Single and Multiple Black-box Predictors
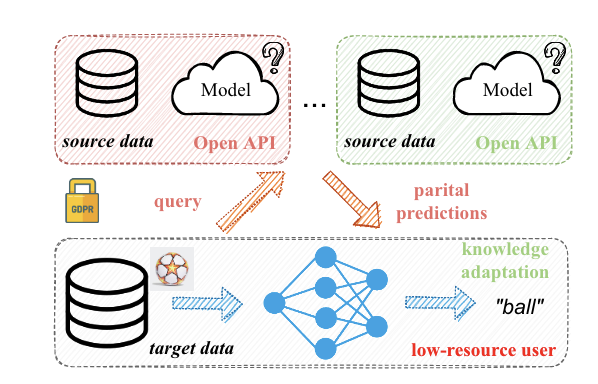
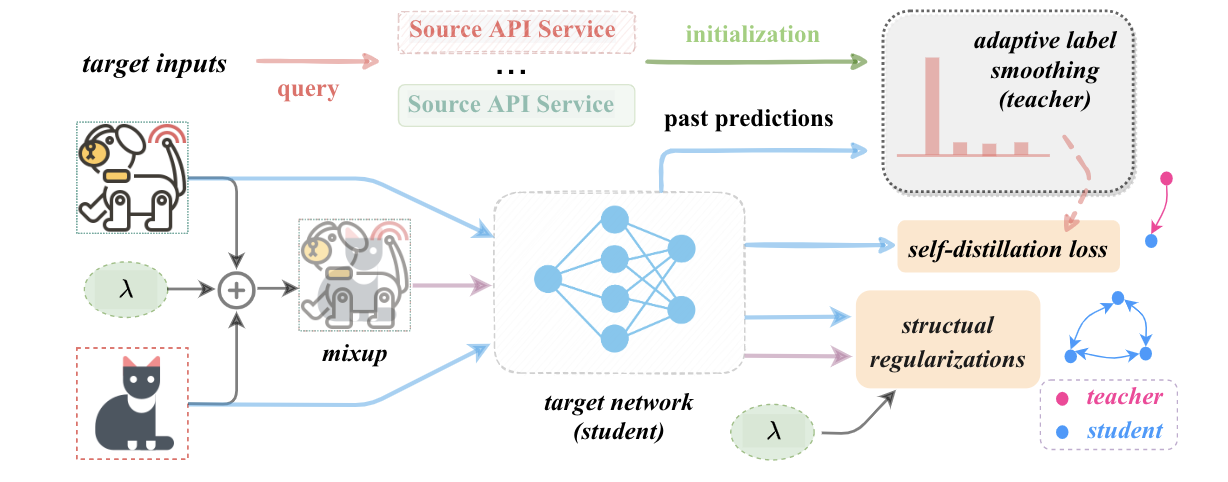

Black-box Modal & Knowledge Distillation

