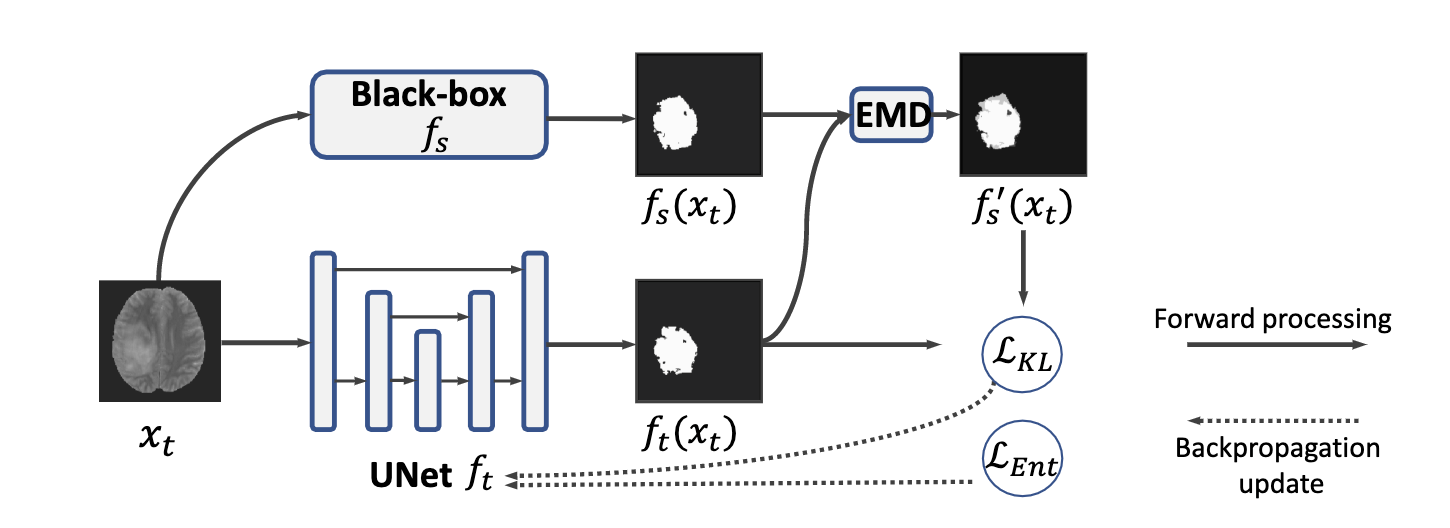
2022-08-15发表2025-11-25更新论文阅读12 分钟读完 (大约1810个字)Black-box Modal & Knowledge DistillationUnsupervised Domain Adaptation for Segmentation withBlack-box Source Model阅读更多